What’s New🔥
Keep track of Smartcat’s latest product updates based on industry trends and user feedback!
All product releases, listed and explained

Want a more in-depth run-through? Feel free to book a meeting with one of our localization experts.
Book a demoApril 24, 2024
Coming soon: AI dubbing and video subtitle Editor

March 26, 2024
Introducing Smartcat’s NEW Translation Memory Editor for more control and translation consistency

March 18, 2024
Now get live Figma translation previews
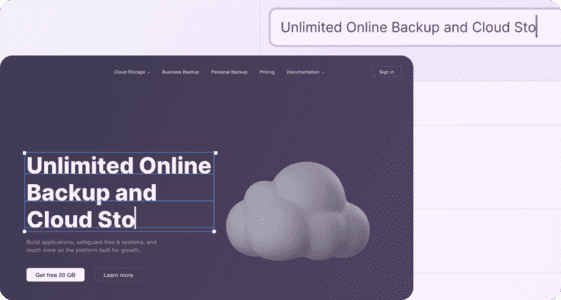
February 29, 2024
Introducing an enhanced Figma experience with Smartcat

December 15, 2023
Maximize translation performance with Translation Quality Score by Smartcat
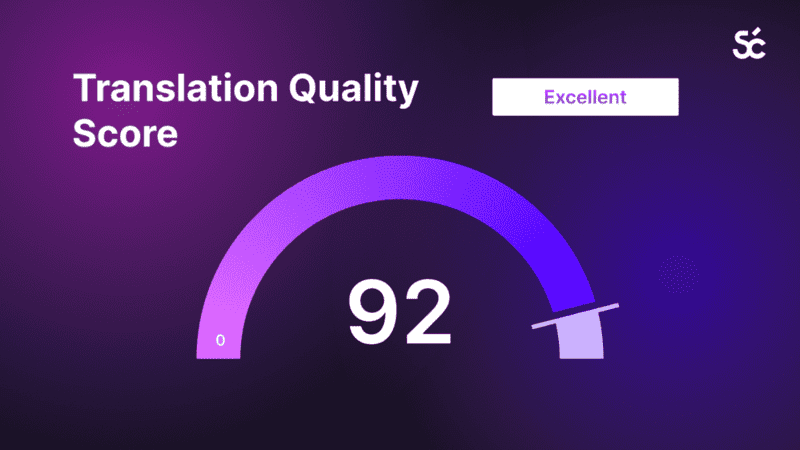
December 3, 2023
Now use estimated words to plan translation budgeting with more precision
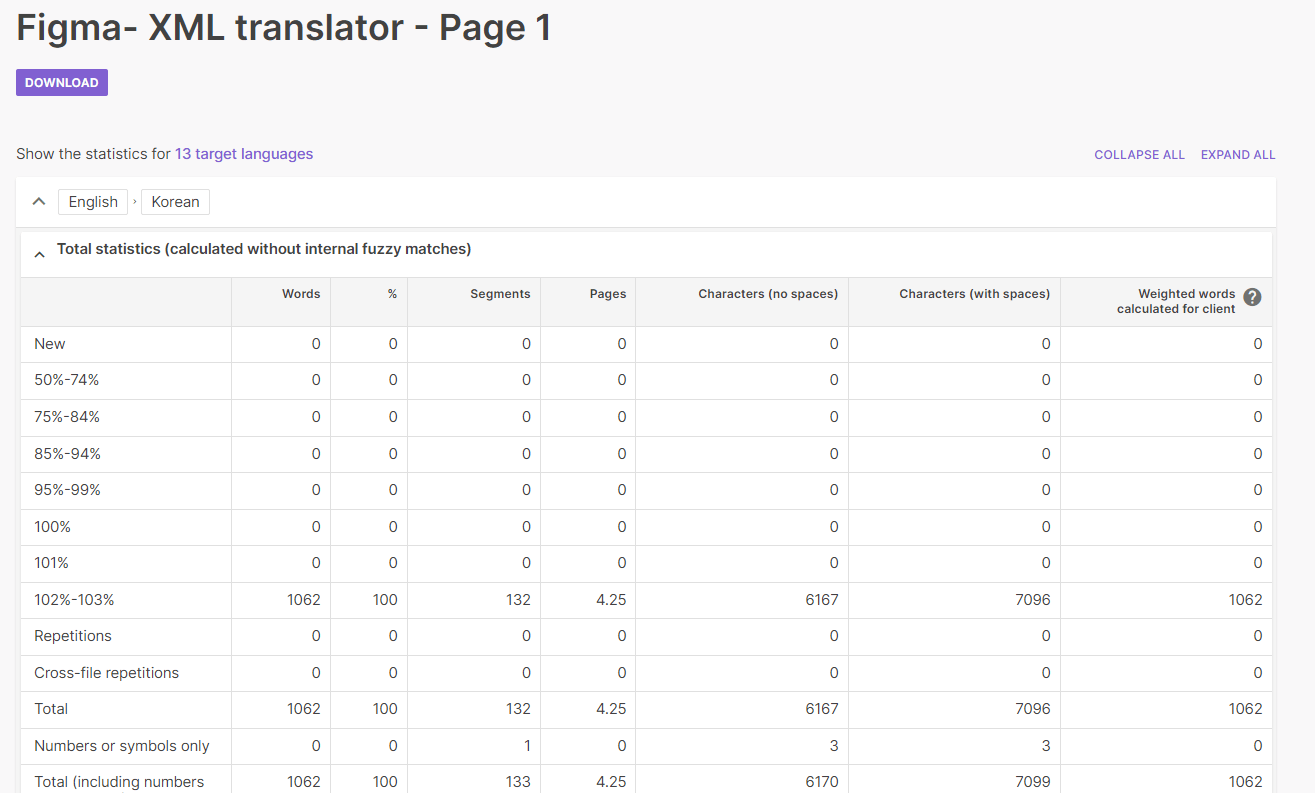
November 28, 2023
Now view workspaces in different geo-zones on your home page
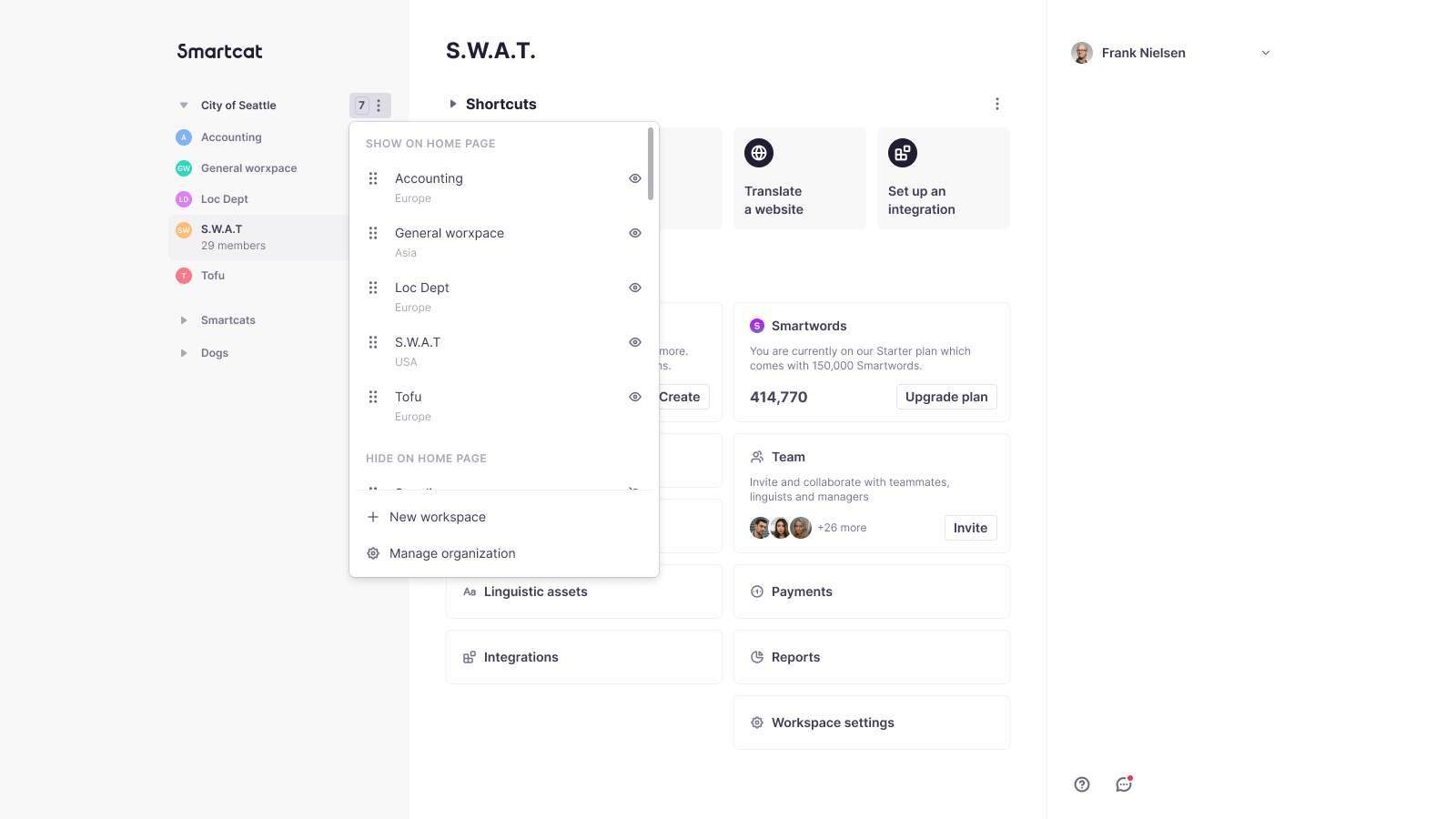
November 15. 2023
Discover enhanced LQA projects and review mode in the Smartcat Editor
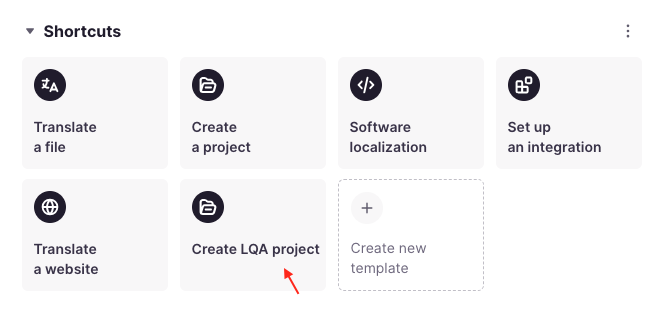
October. 12 2023
It's now easier to join or invite colleagues to existing company workspaces on Smartcat
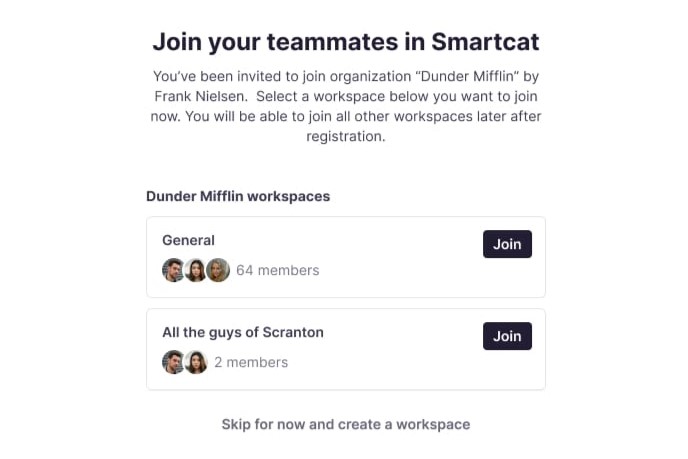
October 6, 2023
Continuous & automatic synchronization for WordPress translations via Smartcat
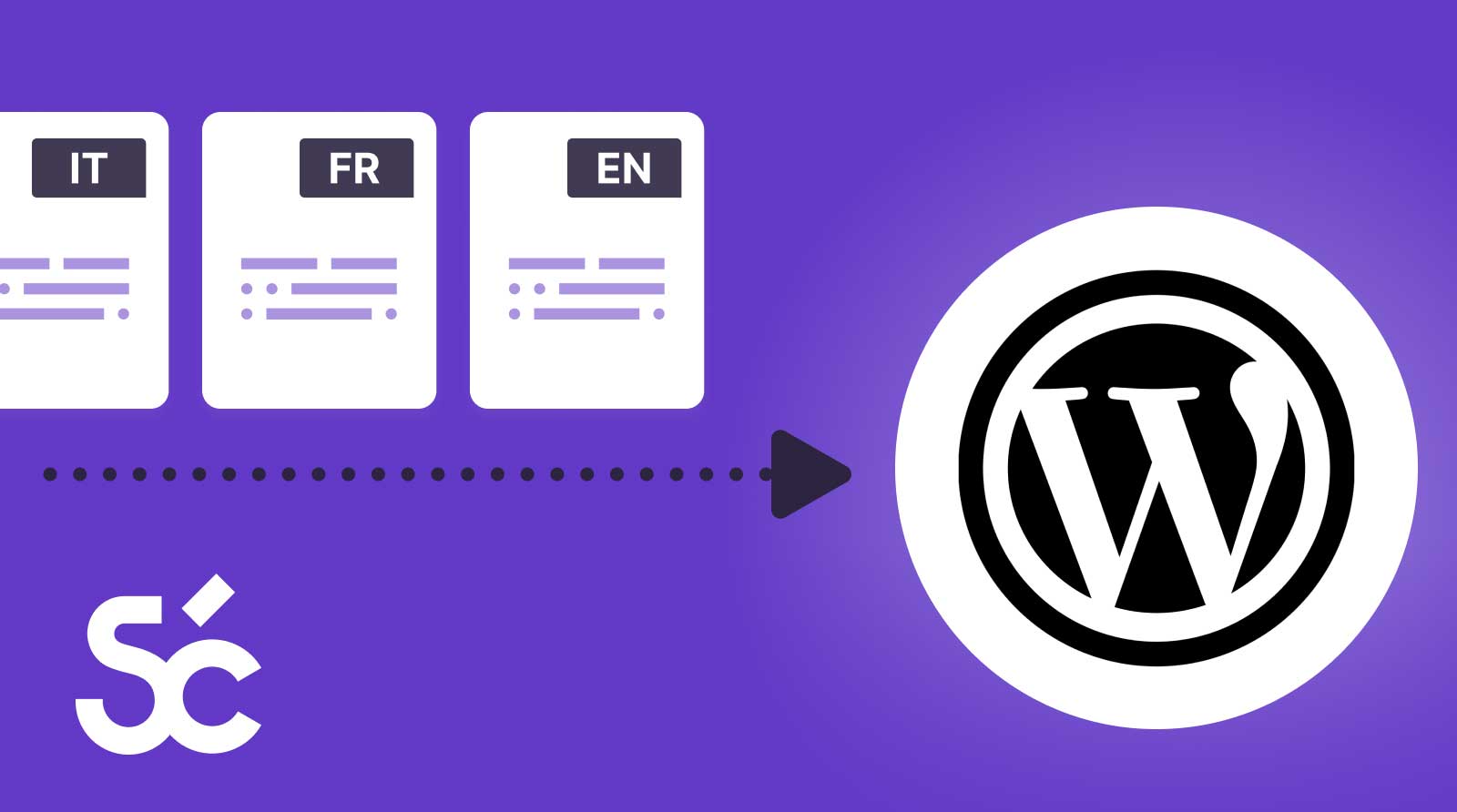
October 1, 2023
Introducing the all-new Projects Overview Page
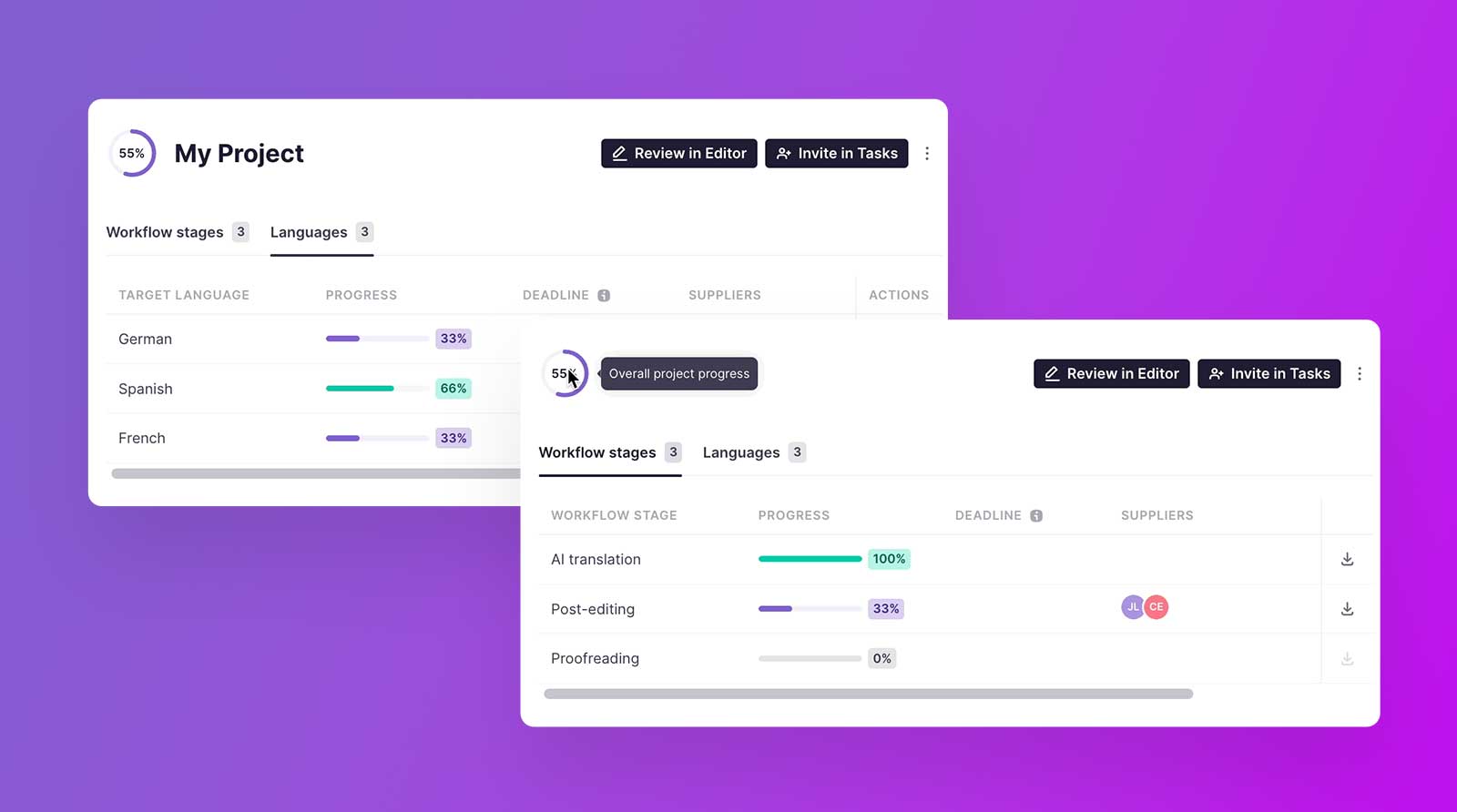
September 6, 2023
NEW threaded segment comments are here to boost communication and translation quality
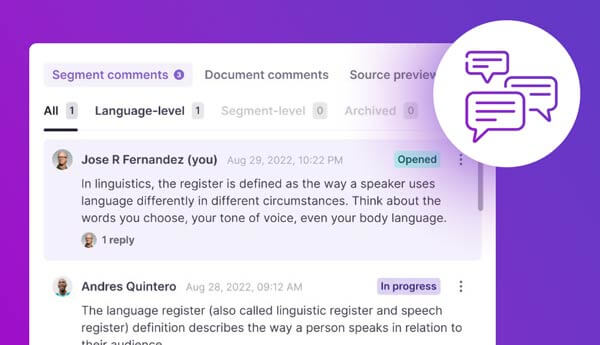
August 9, 2023
Smartcat AI: The all-in-one generative AI content and translation solution [beta launch]
![Smartcat AI: The all-in-one generative AI content and translation solution [beta launch]](https://s3-promo-content.s3-eu-west-1.amazonaws.com/_promo-content/1691598905027Untitled__500___288_px___1_.png)
June 26, 2023
Export Videos with Burned-in Subtitles Instantly!

June 15, 2023
Payable jobs page on Smartcat gets a huge update: easier, more flexible, and clearer

May 8, 2023
Make your subtitles source text perfect before translating
May 4, 2023
Smartcat releases the most contextual, configurable, and reusable AI translation and AI Actions
April 18, 2023
Easily translate software UI designs with our developer-friendly Figma integration
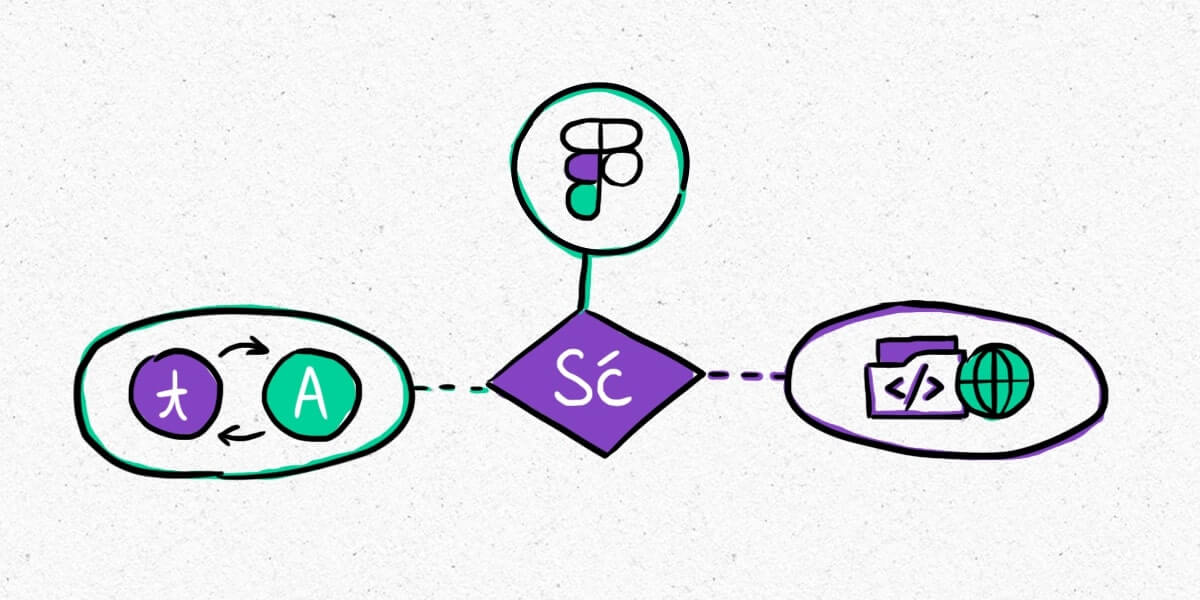
April 12, 2023
Updated payment flow for translation service invoices

April 12, 2023
Smartcat Editor features update
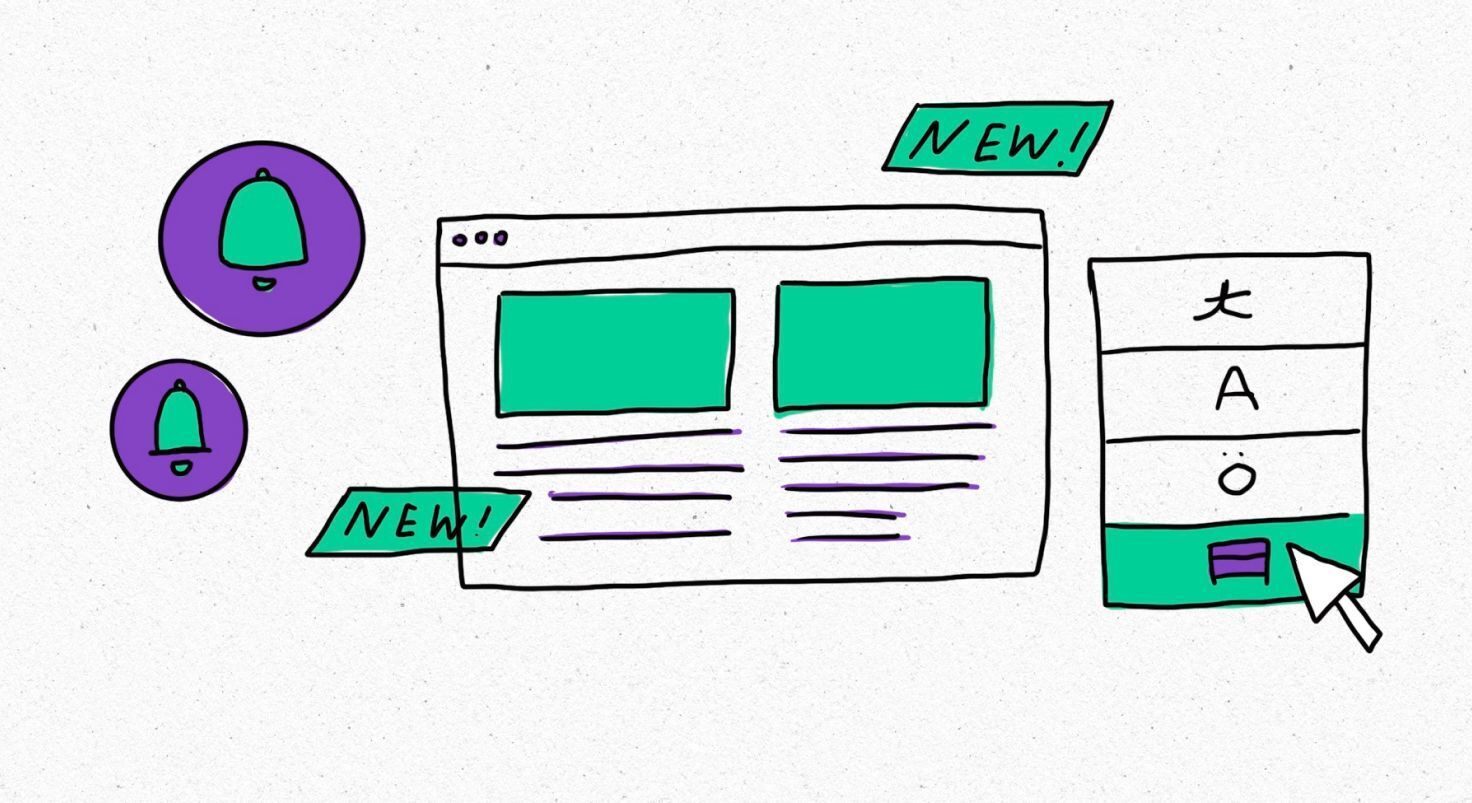
April 12, 2023
Upload video and audio files directly to Smartcat for instant transcription translation
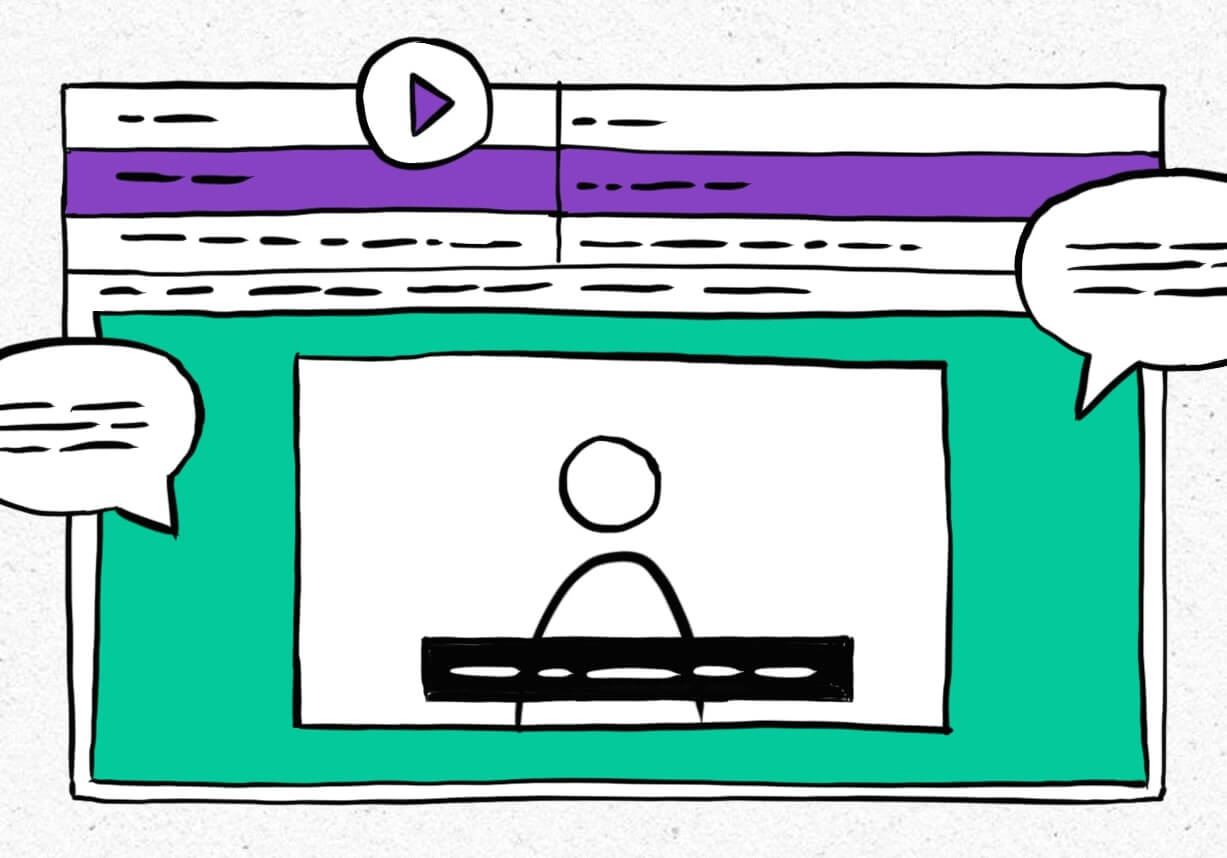
March 30, 2023
Software localization made easy and collaborative across teams with latest Smartcat release
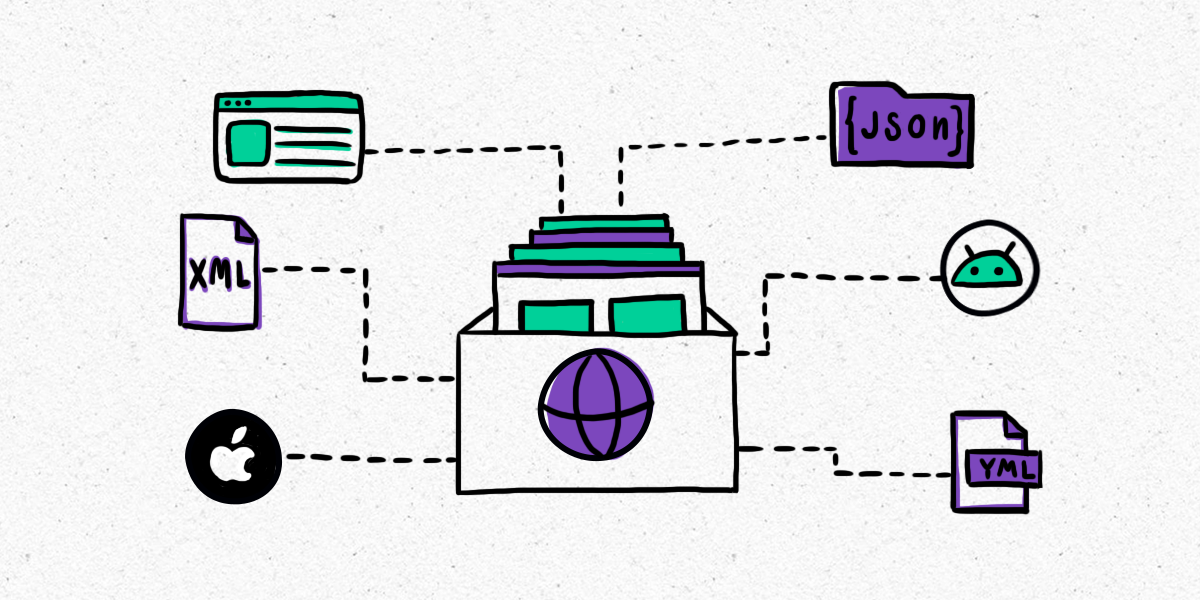
March 10, 2023
Smartcat now lets you top up your balance in multiple currencies and via wire transfer
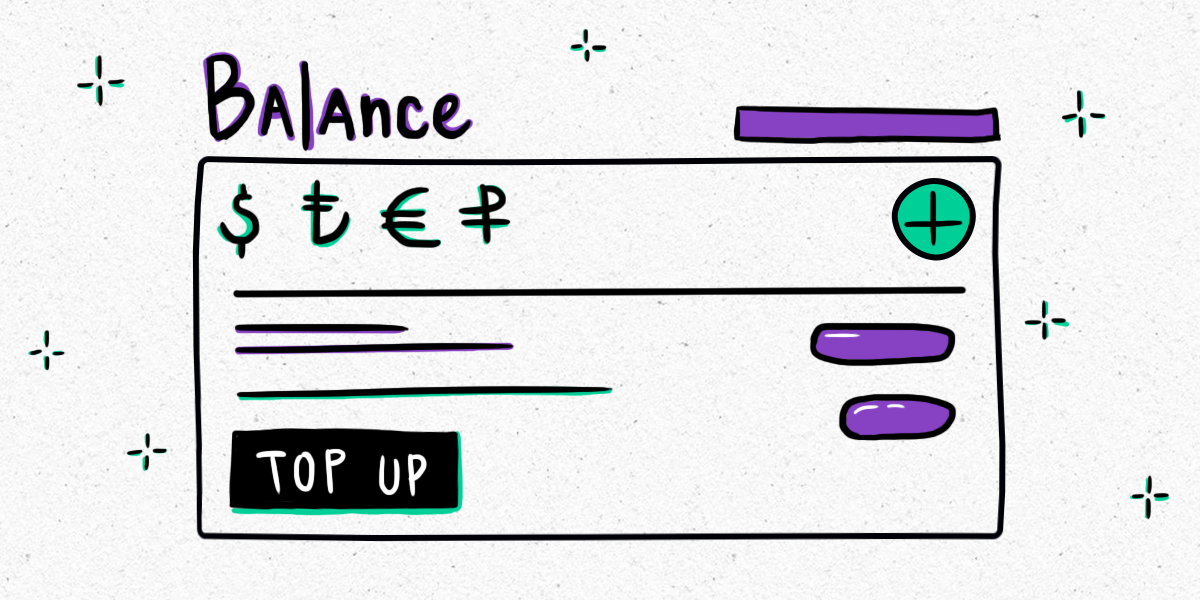
March 2, 2023
Get peace of mind with new machine translation backup to safeguard your translation performance!
February 27, 2023
Effortless and continuous Wordpress translation with Smartcat’s new Elementor plugin integration

February 23, 2023
New automatic invoicing and settings for quick and easy end-of-the-month supplier payments
Feb 10 2023
Your Smartwords usage history always at hand
Feb 1 2023
Speed up your search with new Editor filters
Dec 6, 2022
Manage your content translations without leaving WordPress

Nov 28, 2022
Add context at the segment level
Nov 22, 2022
Welcome the most significant Smartcat update ever!
Nov 1, 2022
Take language quality assurance to enterprise level
Oct 21, 2022
Leave comments literally anywhere to improve results on an even more granular level!

October 14, 2022
Smartcat now supports XLIFF 2.0!
October 7, 2022
Editor 2.0: Designed with you in mind
September 30, 2022
Translate right in Google Sheets with our new Integration
September 23, 2022
Making website translation easier at each stage
September 16, 2022
Sharing tasks becomes even simpler with our new Sharing Tool

August 22, 2022
Ship content for your digital products faster with our Contentful integration
August 20, 2022
Open up to buyers across the globe
July 29, 2022
Make localization agile with our new Jira integration
July 26, 2022
More flexibility with our WPML connector
July 15, 2022
Drupal integration revamp: connect your website to Smartcat via TMGMT
July 13, 2022
Website Translator: our new plug-and-play solution that works with any CMS
April 23, 2022
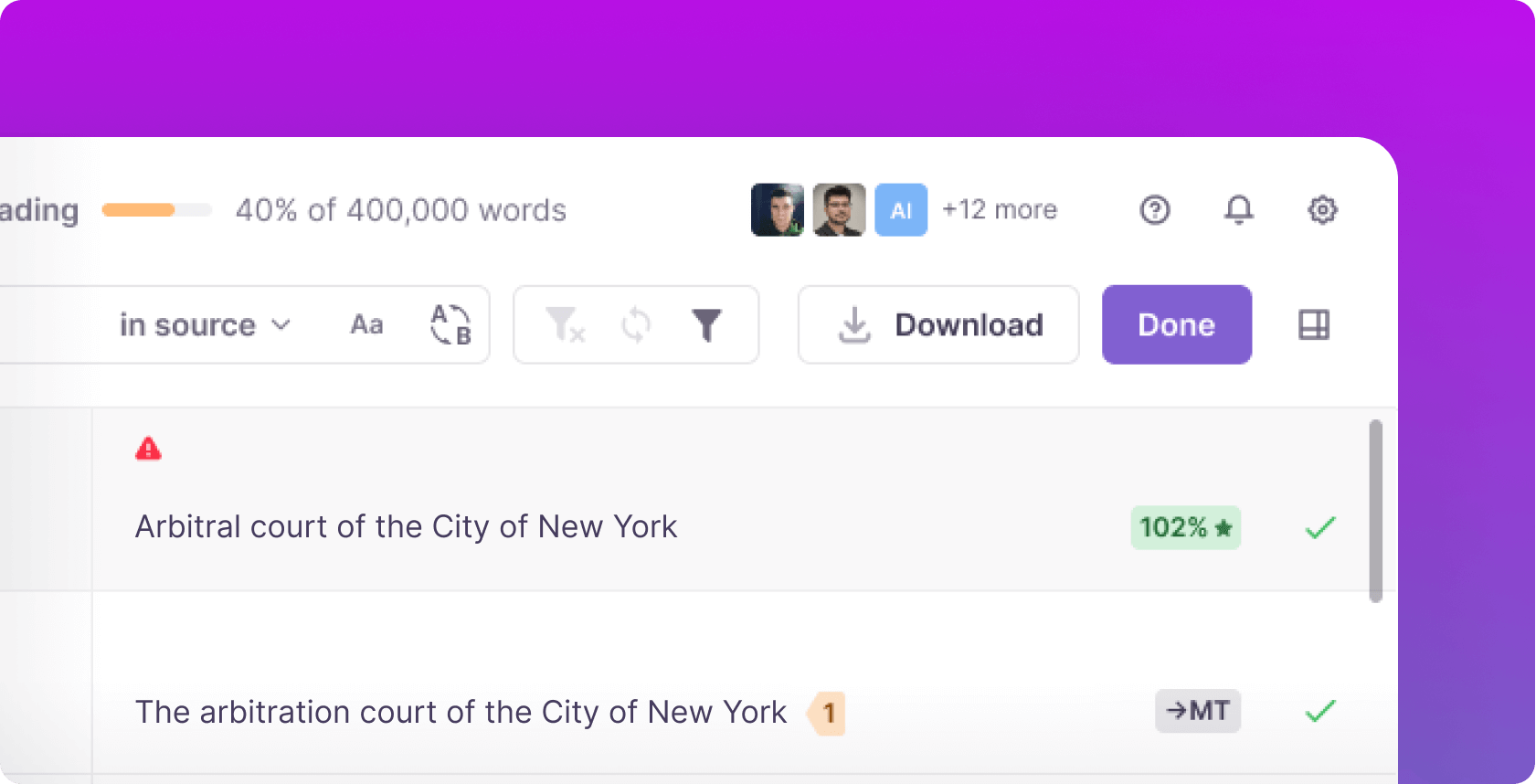
Introducing our Revamped Home Page Experience

March 29, 2022
Reinvent your translation environment with new customizable Smartcat editor
February 20, 2022
Reach out to new audiences with video subtitles translated in Smartcat
February 20, 2022
Smartcat Translator for Desktop

February 7, 2022
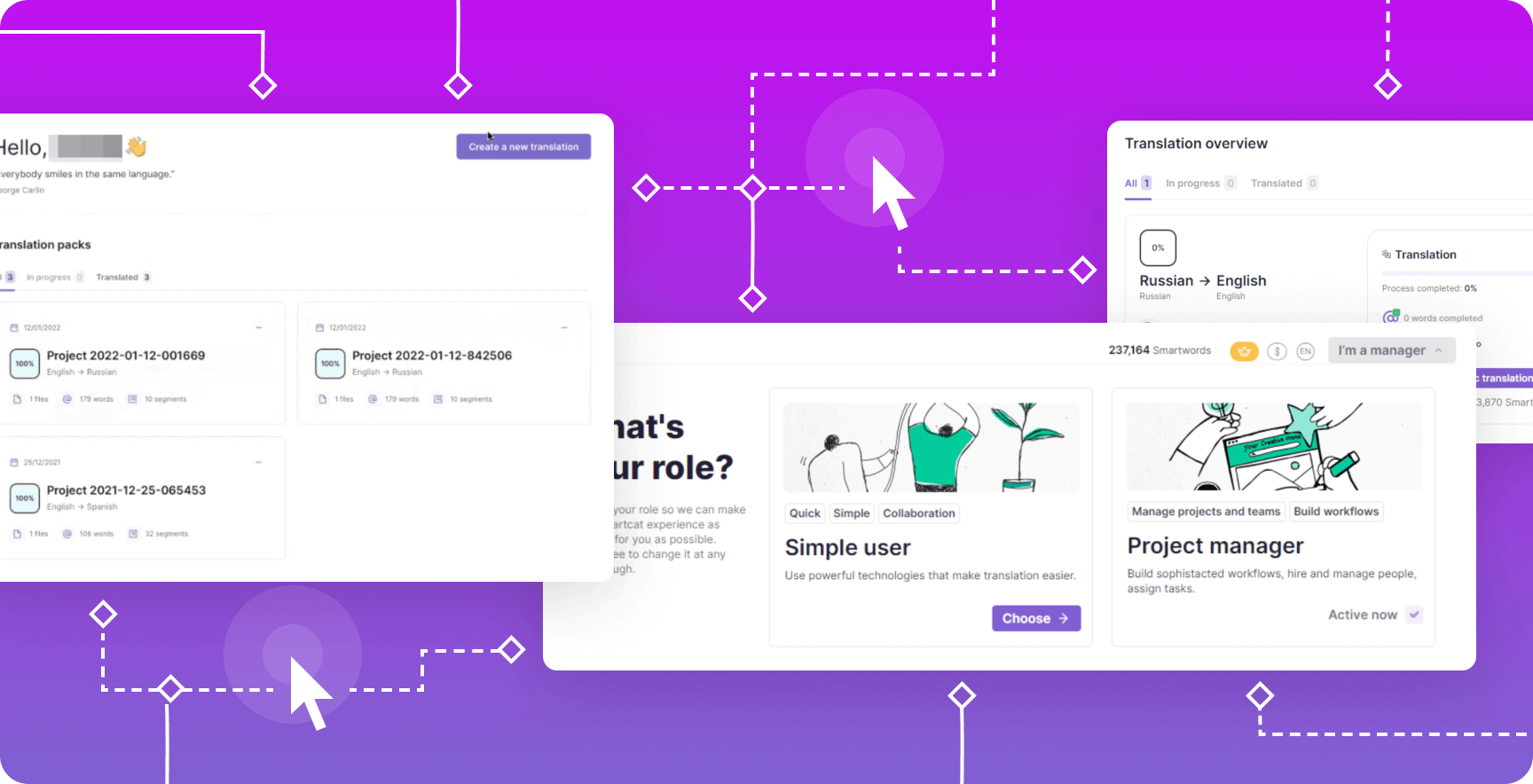
Meet the brand new Smartcat UX with role-based user experience
December 14, 2021
Transform monolingual Figma files into multilingual with Smartcat connector

December 9, 2021
Improve translation quality with Smartcat’s Linguistic Quality Assurance (LQA) tool

November 23, 2021
Use Smartcat to automate localization of your Akeneo account

November 15, 2021
Automating project translation with Smartcat’s Autopilot

November 8, 2021
Importing multiple jobs for payment
